Key Idea: We leverage semantic structure in a pretrained dense model's activations to initialize both experts and the router in MoE upcycling, breaking expert symmetry and promoting early specialization.
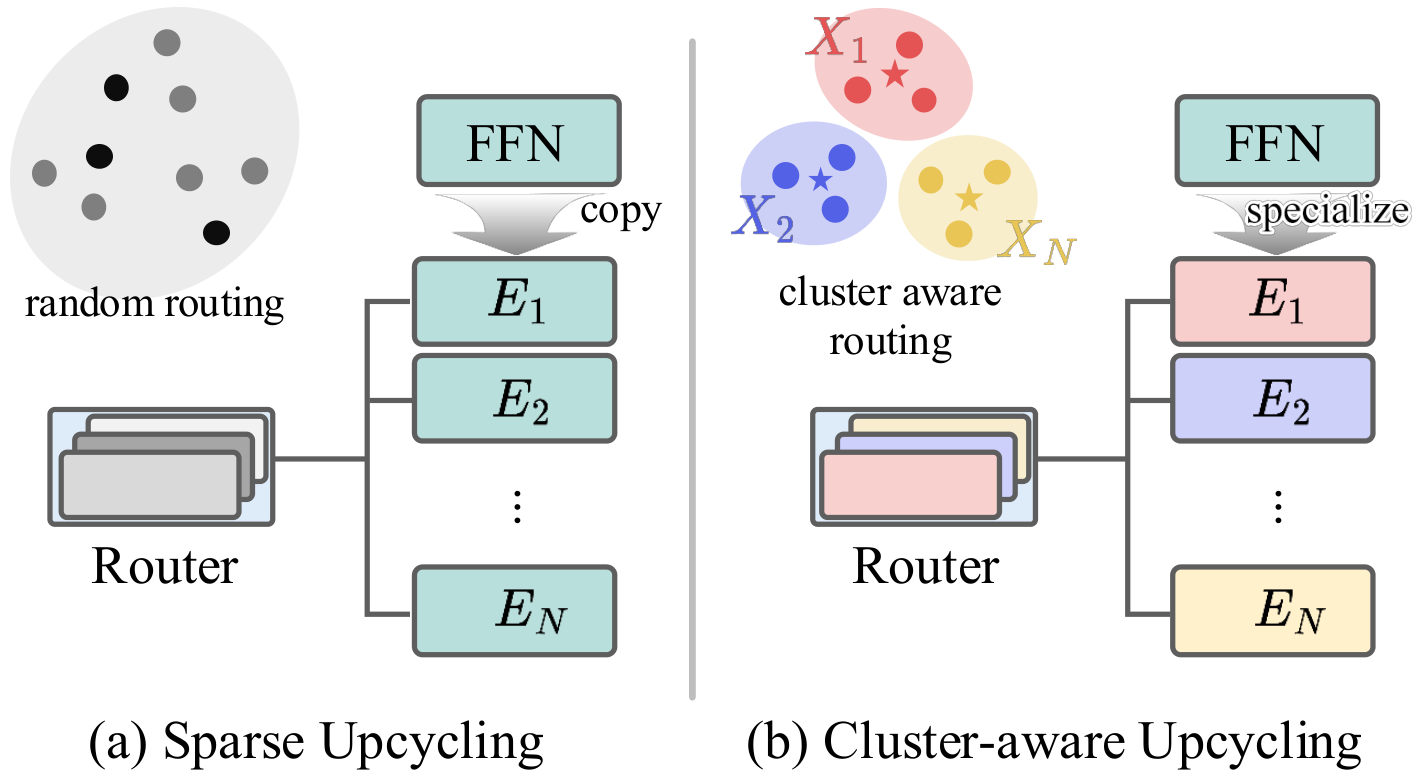
Sparse Upcycling provides an efficient way to initialize a Mixture-of-Experts (MoE) model from pretrained dense weights instead of training from scratch. However, since all experts start from identical weights and the router is randomly initialized, the model suffers from expert symmetry and limited early specialization. We propose Cluster-aware Upcycling, a strategy that incorporates semantic structure into MoE initialization. Our method first partitions the dense model's input activations into semantic clusters. Each expert is then initialized using the subspace representations of its corresponding cluster via truncated SVD, while setting the router's initial weights to the cluster centroids. This cluster-aware initialization breaks expert symmetry and encourages early specialization aligned with the data distribution. Furthermore, we introduce an expert-ensemble self-distillation loss that stabilizes training by providing reliable routing guidance using an ensemble teacher. When evaluated on CLIP ViT-B/32 and ViT-B/16, Cluster-aware Upcycling consistently outperforms existing methods across both zero-shot and few-shot benchmarks. The proposed method also produces more diverse and disentangled expert representations, reduces inter-expert similarity, and leads to more confident routing behavior.
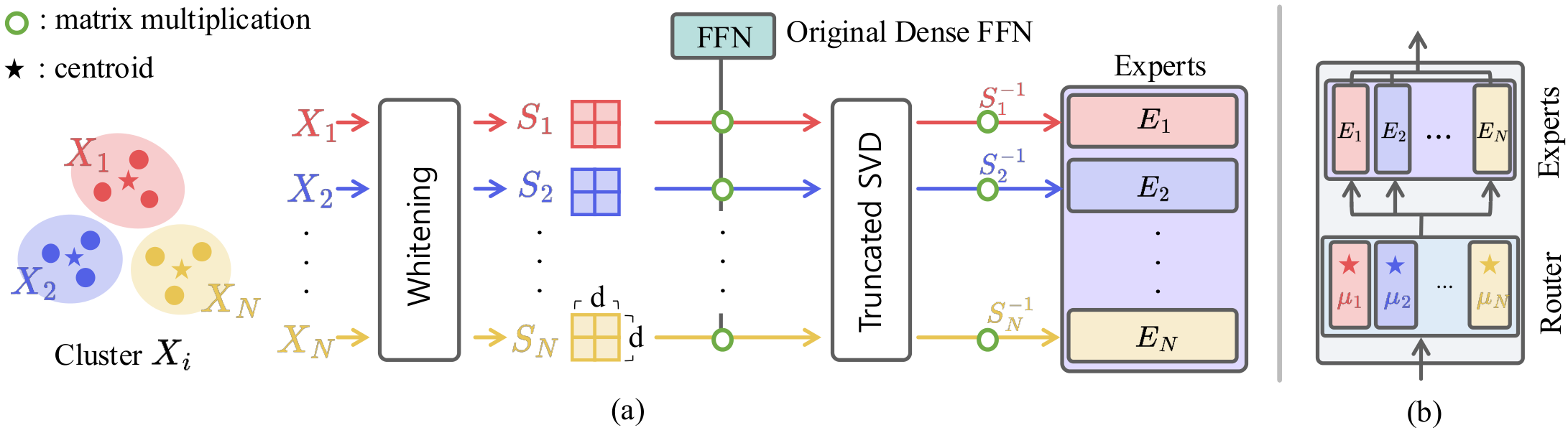
The initialization pipeline consists of three components:
Input activations from each FFN block are partitioned via spherical k-means clustering based on cosine similarity, which directly aligns with the router's logit computation.
Each expert is initialized to capture the principal subspace of its corresponding cluster, preserving pretrained knowledge within the assigned semantic region while promoting diversity across experts.
The router weights are set to the cluster centroids, ensuring that early routing decisions align with the data's semantic structure rather than random routing.
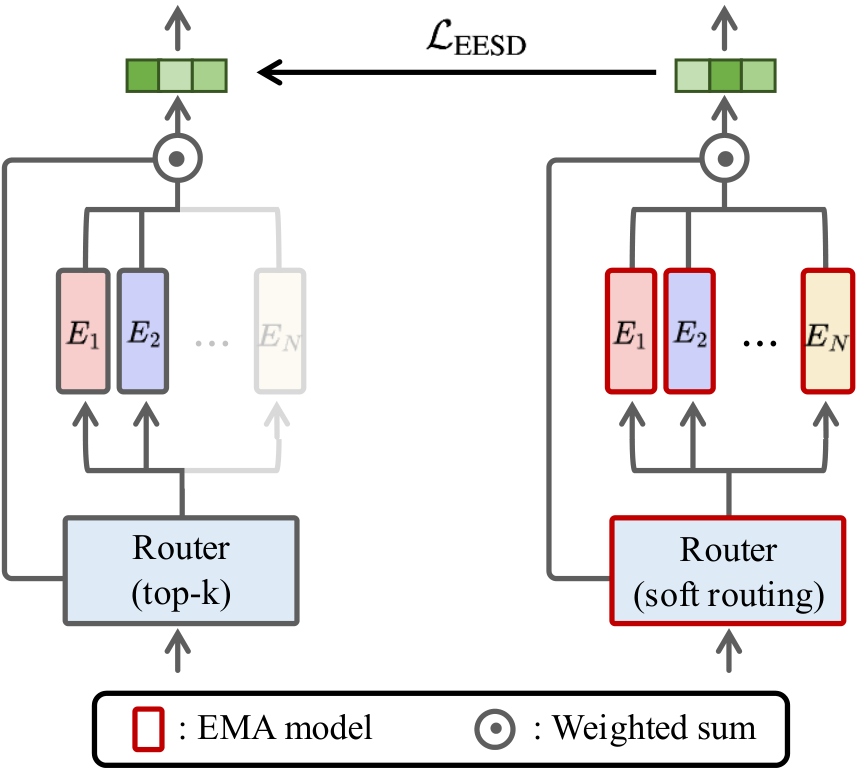
Tokens with near-uniform routing probabilities indicate weak alignment between input and experts, making it difficult to preserve and reinforce consistent specialization. The Expert-Ensemble Self-Distillation (EESD) loss addresses this using a dense EMA ensemble teacher that activates all experts simultaneously, providing stable supervision for the sparse MoE model. This provides stronger guidance when routing is uncertain, while remaining small for confident tokens. EESD introduces only modest overhead in our experiments: ~5.3% in wall-clock time and ~2.8% in GPU memory.
Zero-shot retrieval (MSCOCO, Recall@1) and classification accuracy on CLIP ViT-B/16. Cluster-aware Upcycling achieves the best performance across most benchmarks.
| Method | MSCOCO | ImageNet-1k | VTAB Nat. |
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| I→T | T→I | Avg. | Val | V2 | A | R | Sketch | ObjNet | Avg. | ||
| Dense | 34.3 | 50.8 | 42.6 | 62.5 | 54.4 | 23.5 | 70.6 | 45.8 | 42.5 | 49.9 | 62.6 |
| Drop-Upcycling | 34.1 | 51.3 | 42.7 | 62.0 | 54.5 | 22.7 | 70.8 | 45.7 | 42.9 | 49.8 | 60.9 |
| Sparse Upcycling | 34.9 | 50.9 | 42.9 | 63.0 | 55.1 | 23.7 | 71.2 | 46.3 | 42.3 | 50.3 | 62.0 |
| CLIP-MoE | 34.0 | 51.5 | 42.8 | 62.9 | 54.9 | 24.5 | 71.6 | 46.2 | 43.4 | 50.6 | 62.8 |
| Cluster-aware Upcycling (Ours) | 35.4 | 51.6 | 43.5 | 63.2 | 55.1 | 24.1 | 72.1 | 46.8 | 43.5 | 50.8 | 63.3 |
ImageNet-1k few-shot and full fine-tuning accuracy on the upcycled ViT-B/16. Improvements are most pronounced in few-shot regimes, where initialization quality is critical due to limited training signals.
| Method | 5-shot | 10-shot | Full FT |
|---|---|---|---|
| Dense | 50.4 | 57.1 | 72.8 |
| Sparse Upcycling | 50.9 | 57.8 | 73.0 |
| Drop-Upcycling | 51.1 | 57.9 | 73.1 |
| CLIP-MoE | 51.3 | 58.0 | 73.2 |
| Cluster-aware Upcycling (Ours) | 51.5 | 58.2 | 73.3 |
Cluster-aware initialization and EESD play complementary roles. EESD alone shows modest gains, but combined with cluster-aware initialization it yields further improvements across all benchmarks.
| Cluster-init. | EESD | MSCOCO I→T | MSCOCO T→I | IN Val | IN 10-shot |
|---|---|---|---|---|---|
| 34.9 | 50.9 | 63.0 | 57.8 | ||
| ✓ | 35.1 | 51.1 | 63.2 | 58.1 | |
| ✓ | 34.6 | 51.4 | 62.7 | 57.8 | |
| ✓ | ✓ | 35.4 | 51.6 | 63.2 | 58.2 |
We analyze how Cluster-aware Upcycling influences expert specialization across four dimensions, quantitatively confirming that our method mitigates expert symmetry and redundancy.
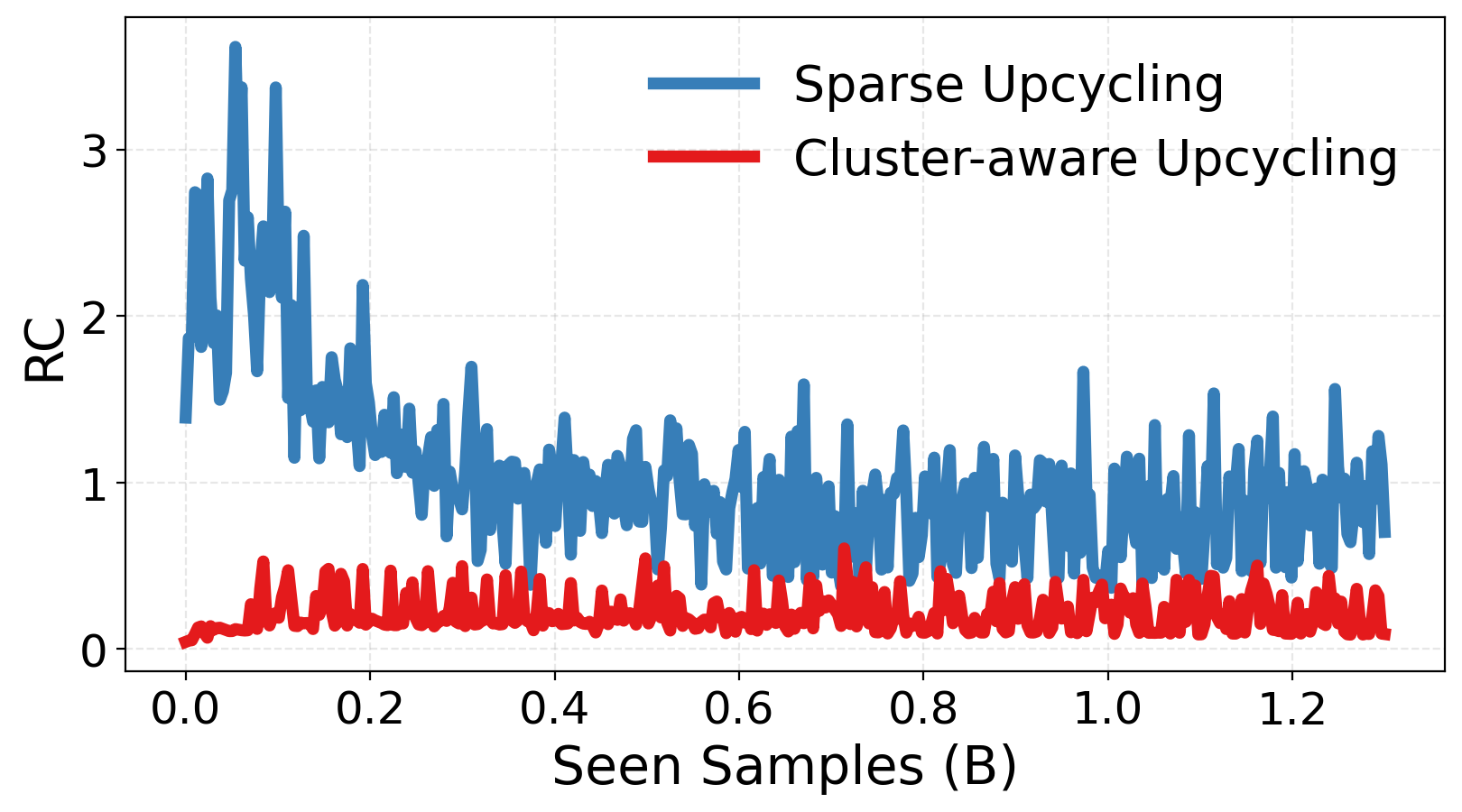
(a) Relative Compactness. Measures overlap between intra- and inter-expert variance. Lower values indicate more disentangled, geometrically independent expert subspaces.
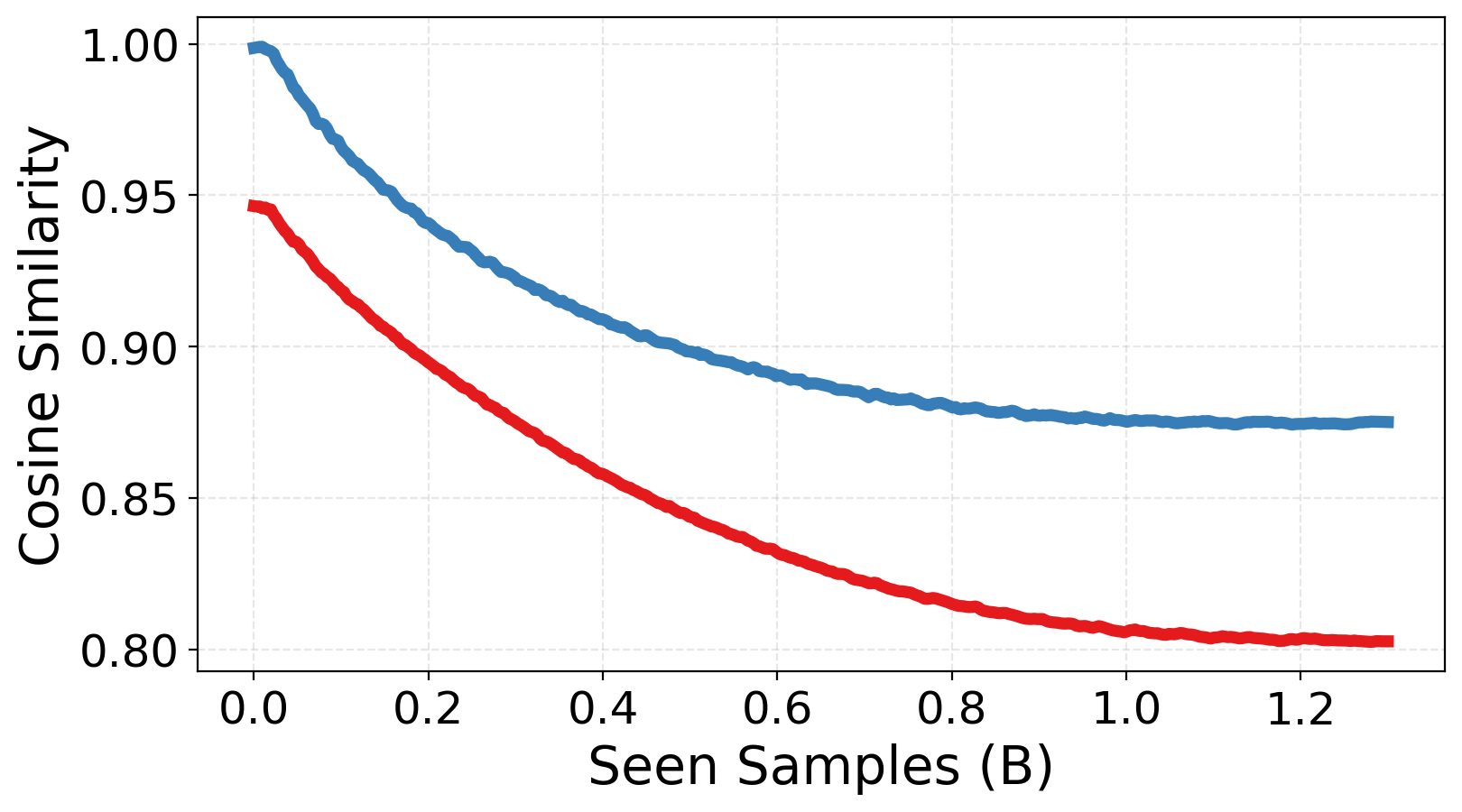
(b) Expert Similarity. Pairwise cosine similarity between expert weights. Cluster-aware Upcycling maintains significantly higher parameter diversity across experts.
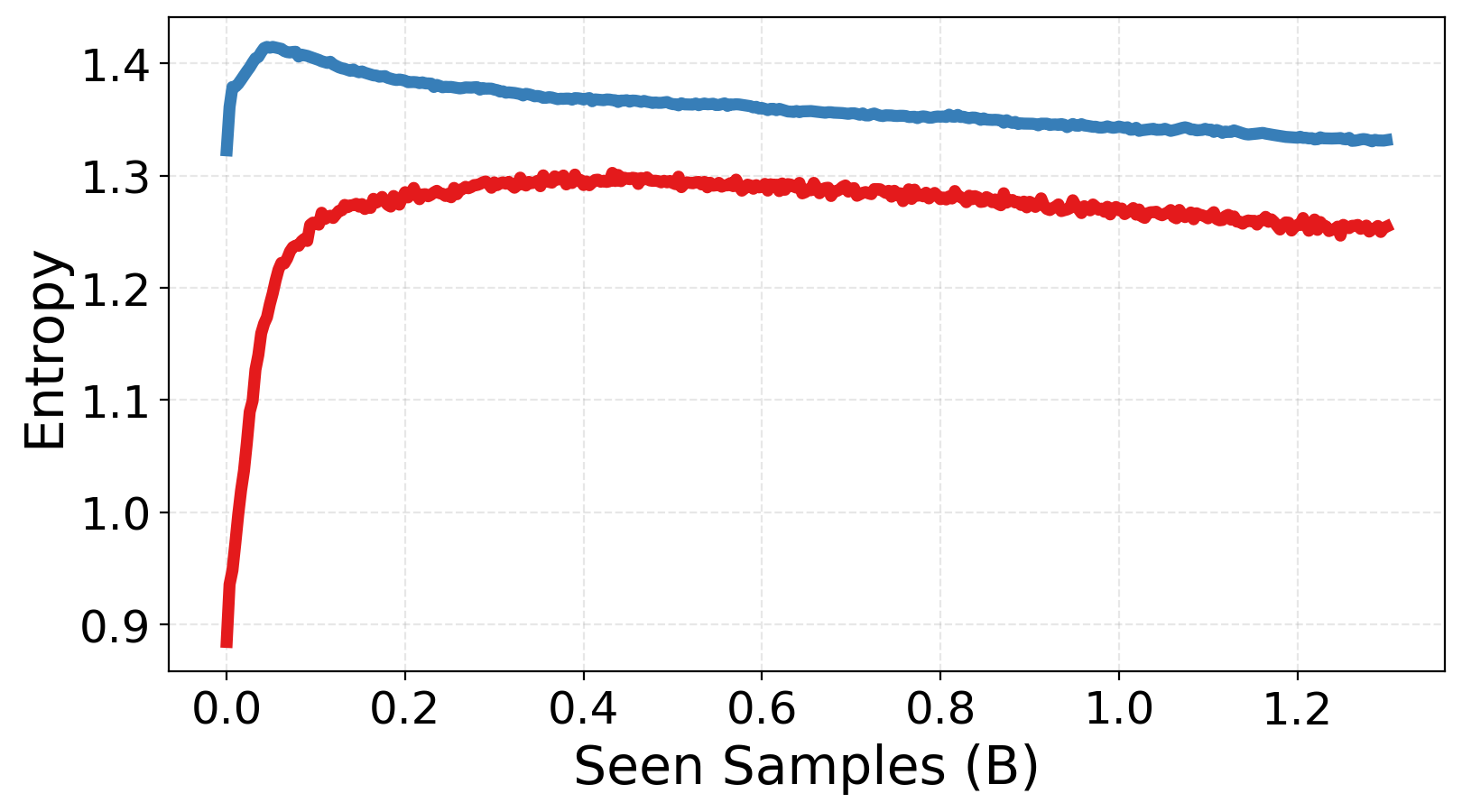
(c) Routing Entropy. Our model starts with low entropy, increases during training as load-balancing encourages exploration, and stabilizes at a lower level than baselines.
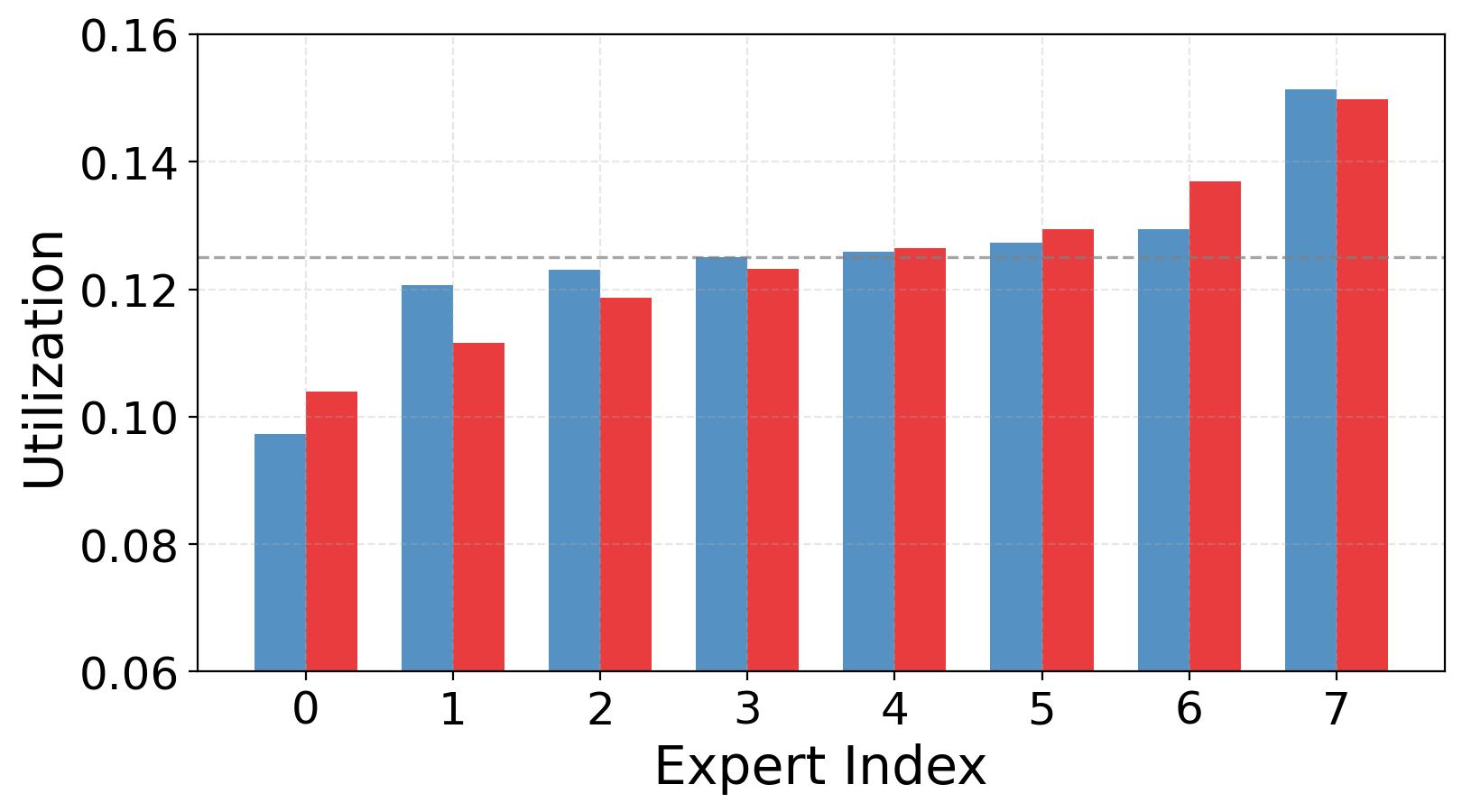
(d) Expert Utilization. Balanced and stable utilization across all experts without routing collapse, confirming structured specialization without imbalance.
Coming soon.